想象一下,当你驾驶一辆自动驾驶汽车穿过隧道时,你却不知道前方发生了一起车祸,导致交通中断。通常情况下,你需要依靠前面的汽车来判断是否应该开始刹车。但如果你的汽车能够看到前方车辆的情况,并更早地踩下刹车,情况会怎样?
麻省理工学院和Meta 的研究人员开发出一种计算机视觉技术,有朝一日可以使自动驾驶汽车做到这一点。
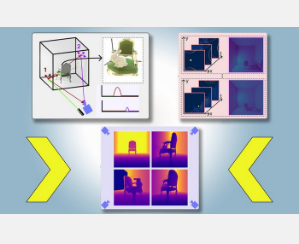
他们介绍了一种方法,利用来自单个摄像机位置的图像,创建整个场景(包括视线受阻的区域)的物理精确 3D 模型。他们的技术利用阴影来确定场景中受阻部分的内容。
他们将自己的方法称为 PlatoNeRF,基于柏拉图的洞穴寓言,这是古希腊哲学家《理想国》中的一段话, 其中被锁在山洞中的囚犯根据投射在洞穴墙壁上的阴影来辨别外部世界的现实。
通过将激光雷达(光检测和测距)技术与机器学习相结合,PlatoNeRF 可以生成比现有 AI 技术更精确的 3D 几何重建。此外,PlatoNeRF 更擅长平滑地重建阴影难以看到的场景,例如环境光强或背景较暗的场景。
除了提高自动驾驶汽车的安全性之外,PlatoNeRF 还可以让用户无需走动测量即可对房间的几何形状进行建模,从而提高 AR/VR 头戴设备的效率。它还可以帮助仓库机器人更快地在杂乱的环境中找到物品。
“我们的核心理念是将这两个之前在不同学科中完成的东西结合起来——多反射激光雷达和机器学习。事实证明,当你将这两者结合在一起时,你会发现很多新的机会去探索并充分利用两全其美,”麻省理工学院媒体艺术与科学研究生、麻省理工学院媒体实验室成员、PlatoNeRF论文的主要作者 Tzofi Klinghoffer 说。
克林霍夫 与他的导师、麻省理工学院媒体艺术与科学副教授兼相机文化小组负责人 Ramesh Raskar、Meta Reality Labs 人工智能研究 主任、资深作者 Rakesh Ranjan,以及麻省理工学院的 Siddharth Somasundaram 和 Meta 的 Xiaoyu Xiang、Yuchen Fan 和 Christian Richardt 共同撰写了这篇论文。这项研究将在计算机视觉和模式识别会议上发表。
阐明问题
从一个摄像机视点重建完整的 3D 场景是一个复杂的问题。
一些机器学习方法采用生成式人工智能模型来猜测被遮挡区域中的物体,但这些模型可能会产生幻觉,而这些物体实际上并不存在。其他方法则尝试使用彩色图像中的阴影来推断隐藏物体的形状,但当阴影难以看清时,这些方法可能会遇到困难。
对于 PlatoNeRF,麻省理工学院的研究人员利用一种名为单光子激光雷达的新传感方式构建了这些方法。激光雷达通过发射光脉冲并测量光反射回传感器所需的时间来绘制 3D 场景。由于单光子激光雷达可以探测单个光子,因此它们可以提供更高分辨率的数据。
研究人员使用单光子激光雷达照亮场景中的目标点。一些光从该点反射并直接返回传感器。然而,大多数光在返回传感器之前会散射并从其他物体反射回来。PlatoNeRF 依赖于这些光的第二次反射。
通过计算光线反射两次并返回激光雷达传感器所需的时间,PlatoNeRF 可以捕获有关场景的其他信息,包括深度。第二次反射的光线还包含有关阴影的信息。
该系统追踪次级光线(从目标点反射到场景中其他点的光线),以确定哪些点处于阴影中(由于没有光线)。根据这些阴影的位置,PlatoNeRF 可以推断出隐藏物体的几何形状。
激光雷达依次照亮 16 个点,捕获多幅图像,用于重建整个 3D 场景。