通过双通道共识增强多智能体协调
许多现实世界的多智能体场景可以自然地建模为部分可观察的合作多智能体强化学习 (MARL) 问题。智能体以分散的方式行动,并被赋予不同的观察结果。对其他智能体的状态和行动的不确定性可能会阻碍协调,特别是在分散顺序执行期间,从而导致灾难性的协调不力和次优策略。
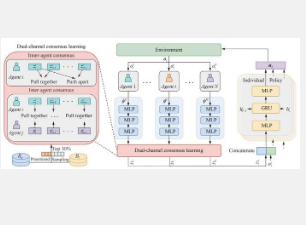
在这种多智能体系统中成功实现协调通常需要智能体达成共识。实现此目标的最常见方式是通过信息共享。通过为智能体配备信息共享技能,可以缓解许多挑战,例如部分可观察性和非平稳性。最近的方法要么使用通信协议显式交换消息,要么通过行为建模和集中训练隐式共享信息。
显式信息共享严重依赖于通信渠道的存在,而在现实场景中,通信渠道可能受到传输带宽、成本、信息延迟等限制。隐式共享需要学习行为预测模型(行为建模)或集中式学习器(集中式训练和分散式执行,CTDE)。行为建模使环境在代理看来是静止的,但不准确的预测模型可能会导致代理行为出现重大偏差。CTDE 使信息在集中式训练中流动,但缺乏在分散式执行期间的信息共享机制。
在这篇发表在《机器智能研究》上的论文中,中国科学院自动化研究所的研究人员提出开发双通道共识(DuCC)来增强多智能体协调。DuCC 通过训练智能体推断出的与同一状态相关的共识表示相似,与不同状态相关的共识表示不同,使智能体能够建立对环境状态的共同理解。这使智能体能够克服部分可观测性的局限性,并一致地评估当前情况(认知一致性),促进它们之间的有效协调。此外,智能体在分散执行过程中独立推断共识表示,并将其用作决策的额外因素。这使得分散执行期间能够及时共享信息,而无需明确的通信。他们的方法非常灵活,可以与各种现有的 MARL 算法相结合以增强协调。
具体而言,研究人员使用对比表示学习来学习反映 DuCC 的共识表示。对比表示学习使用对比损失函数来区分相似和不相似的实例,这非常适合建立共同知识,就像 DuCC 的情况一样。研究人员通过三个步骤实现 DuCC。首先,他们引入共识推理模型,将局部观察映射到潜在的共识表示,从而捕获环境决策相关信息。然后,他们设计一个内部代理对比表示学习目标来捕捉缓慢变化的环境特征并随着时间的推移保持每个代理内的缓慢信息动态(内部代理共识)。研究人员还设计了一个跨代理对比表示学习目标,以使多个代理之间的内部代理共识保持一致(跨代理共识),从而实现认知一致性。当学习到的共识表示满足这两个目标时,DuCC 就被认为已经实现。最后,研究人员将共识表示纳入 MARL 算法中以增强多代理协调。
研究人员在星际争霸多智能体挑战赛和谷歌研究足球赛上评估了他们的方法。结果表明,DuCC 显著提高了各种 MARL 算法的性能。特别是,他们的方法与 QMIX 的组合(称为 DuCC-QMIX)优于最先进的 MARL 算法。研究人员还设计了个体共识度量和群体共识度量,以说明两个对比表示学习目标在开发 DuCC 中的效率。共识表示的可视化表明,他们的方法有效地帮助现有的 MARL 算法达成共识。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。