新的人工智能框架增强了情绪分析
社交媒体爱好者倾向于用表情符号、图片、音频或视频来丰富他们的文本帖子,以吸引更多关注。虽然简单,但这种技术具有科学意义:多模态信息在传达情感方面更有效,因为不同的模态相互作用和增强。为了加深对这些相互作用的理解并改进通过模态组合表达的情感的分析,一个中国研究团队引入了一个新颖的两阶段框架,使用两层堆叠的 transformers,这是用于多模态情绪分析的最先进的人工智能模型。这项研究于 5 月 24 日发表在《智能计算》上,这是一本科学合作期刊。
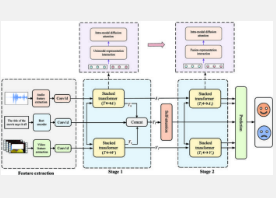
目前,多模态情绪分析的研究通常侧重于融合不同的模态或解决不同类型的融合信息之间复杂的交互或适应性问题。单独使用任何一种方法都可能导致信息丢失。另一方面,该团队的框架分两个阶段融合信息,以有效地捕获两个层面的信息。它在三个开放数据集(MOSI、MOSEI 和 SIMS)上进行了测试,其表现优于或与基准模型相当。
该框架的一般工作流程包括特征提取、两个阶段的信息融合和情感预测。首先,从源视频片段中获取的文本、音频和视频信号通过其相应的特征提取器进行处理,然后与附加的上下文信息一起编码为上下文感知表示。接下来,三种类型的表示首次融合:文本表示与音频和视频表示交互,允许每种模态在此过程中适应其他模态,结果进一步与原始文本表示集成。然后,第一阶段的以文本为中心的输出与调整后的非文本表示融合,以便它们可以相互增强,然后最终丰富的输出即可用于情感预测阶段。
该团队框架的核心是堆叠式变换器,由双向跨模态变换器和变换器编码器组成。这些组件对应两个功能层:双向交互层允许跨模态交互,这是第一阶段融合发生的地方,而细化层则解决更细微的第二阶段融合。
为了提高框架的性能,团队实施了一种注意力权重累积机制,该机制在融合过程中聚合文本和非文本模态的注意力权重,以提取更深层次的共享信息。注意力是 Transformer 中的一个关键概念,它使模型能够识别并关注数据中最相关的部分。该团队的堆叠 Transformer 采用两种类型的注意力机制:双向跨模态 Transformer 使用交叉注意力,Transformer 编码器使用自注意力。
该团队未来的工作将专注于集成更先进的变压器,以提高计算效率并减轻与自注意力机制相关的固有挑战。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。